BLOG
The discourse of the French Method – how to make accessible the knowledge encapsulated in old market gardening manuals?
In may 2023, the CENTRINNO team in Paris organized a workshop dedicated to the French Method which is a set of market gardening practices inspired from Parisian professionals in the 19th century. During this day, we had a discussion about how to make accessible the knowledge encapsulated in the old market gardening manuals.
In 2017, we realized that we were sitting on a formidable heritage of knowledge that had long been completely forgotten. This heritage, made up of market gardening guides from many regions, is first and foremost evidence of the transition from oral transmission to the written archive of agricultural practices. It shows an evolution in the technical approach that we are pursuing two centuries later, using computer sciences as our compass. So we in the SONY computer Sciences Lab, started to gather old gardening manuals in 2017 when trying to get information on the topic. When faced with the huge literature available, we had to find a way around so that we don’t need to read several thousands of pages, relying on digital technologies. So the question about how to make those manuals accessible starts with making the books accessible to machines.
For this, we used computer vision, text mining and natural language processing (NLP) techniques. Before actually manipulating the text, some heavy preprocessing is necessary to detect image and text zones in each page, to turn the text zones into strings of characters using optical character recognition (OCR) and to clean the errors of the OCR using a Bayesian spell checker. We applied this process successfully on a third of the texts in our Good Old Manuals corpus (Figure 1). Some improvement on the computer vision component will be necessary to process some of the remaining texts. The text extracted from these books resulted in around 1M words.

Figure 1: The Good Old Manuals (GOM) corpus was gathered based on advice from specialists on the topic. The ones in the first line (GOM1) are the one we found in the recommended readings list of the Ferme du Bec Hellouin and were used in the text analysis.
The first task on the text was to detect mentions of location and people and connect them to real geographical localization and biographies. This is a classic task in NLP referred to as Named Entities Recognition and Named Entities Linking. For location, we also manually annotated for each location mention whether it is really mentioned as a location or as a variety of fruit or vegetable, like in “Brussels sprout”. From the collection of locations mentioned and the count of their occurrences, we could draw the map on Figure 2, where each circle is indicative of how much the location was mentioned. It appears that Paris and the Paris region is very much cited reflecting the fact that our corpus focuses on Paris practices. It was also possible to draw the social network of the corpus based on the mentions of people.
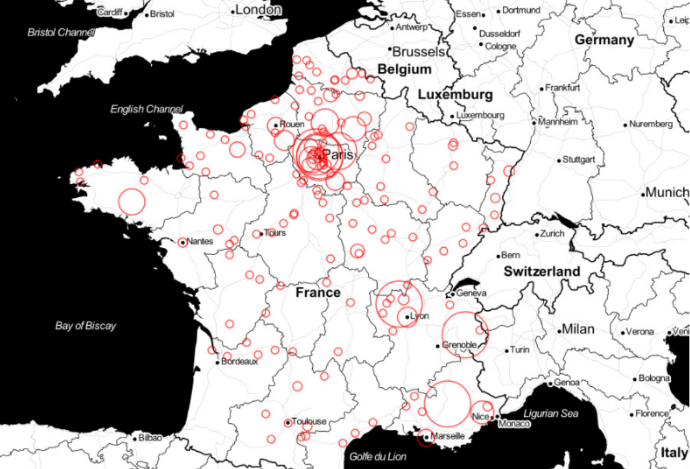
Figure 2: Map of the location mentioned in the GOM1 corpus. Each circle indicates how much it was cited.
It is also possible to explore the verbs by building a semantic map using a language model where verbs with a similar meaning are close together. In this way, we can see what are the verbs corresponding to actions performed by the farmer (like “to water”) or the ones corresponding to biological processes ongoing in the field (like “to bloom“).
To really track the pieces of knowledge in those books, we thought of detecting the causality frame based on an available resource (FrameNet) gathering all elements triggering the causality frame (in French: “car”, “parce que”,…). We were expecting those would give us access to biological knowledge like in the following example from Moreau & Daverne (1845):
“Another observation: practice has taught us that, during the summer, if we water our romaine plants in the hot sun with cold water from our wells, when they are about to be capped or have already been capped, this causes spots of rot inside them; we then say that the romaine is speckled: in this state, it is no longer fit for sale. The same observation has been made of escarole and chicory, when their hearts fill up, when they are ready to be tied or have already been tied, so that it is the rule in our marshes, when these plants have reached this state of growth, to stop watering them in the heat of the sun.”
Here the triggering element is “causes” and the observation reflects some actual biological phenomena. An expert of market gardening, Christian Carnavalet, who was participating in the discussion remarked that this is obvious with nowadays knowledge:
“When you put water on the foliage, the water heats up and allows the fungi to develop. So it’s simply the match between humidity and heat that causes pathogenic fungi to develop.”
It is interesting to see how those pieces of knowledge from the practice can be reinterpreted after 2 centuries of agronomical research and we hope to extract similar examples in a systematic manner.
Lastly, after making the text accessible to machines, the question remains about how to make this accessible to humans and possibly to a large audience. Is the best format a book, a website, a game,…? For now, we decided to create an interactive website (see Figure 3) where the user can navigate the texts, the maps and graphs.

Figure 3: Snapshots of the website designed with Sebastien Marino.
Alexandre Mézard raised an interesting point in the discussion by stating that all knowledge may not be explicitly expressed through text. It is the case of tacit knowledge (a notion invented by Michael Polanyi) which means that human experts and practice will always be necessary in complement to the knowledge from books. Joking, he said the best interface would be to have the visualizations we proposed here with comments from an expert like Christian. All together, our work shows how old pieces of texts can be combined with modern computational techniques to draw new experiences of learning. This hybridization of the new and the old shows that no matter if the knowledge remains the same, its dissemination can find new ways based on the evolution of technologies.
This work is submitted to a text mining conference, we are willing to publish the transcription of the discussion and the website is under construction. So stay tuned on CENTRINNO channels to learn more.